The normalised cut algorithm [88] can cluster a set of elements based only on the values of a similarity measure between all possible pairs of elements. The approach is a spectral clustering method. It is based on the properties of eigenvectors from a matrix computed using the similarities between each pairs of elements.
In the normalised cut scheme, the clustering is seen as a graph partitioning problem. The nodes of the graph are the elements and the weights on the graph edges connecting two nodes are the similarities measured between the two corresponding elements. We use the similarity measure described in the previous section. We seek to partition the graph into subgraphs with high similarities between the nodes of the same subgraphs and a low similarities between nodes from different subgraphs.
Let ![]() be that graph with nodes
be that graph with nodes ![]() and an adjacent graph weight matrix
and an adjacent graph weight matrix ![]() . The element
. The element ![]() of
of ![]() is the similarity measured between the elements represented by the nodes
is the similarity measured between the elements represented by the nodes ![]() and
and ![]() . We can break
. We can break ![]() into two disjoint sets
into two disjoint sets ![]() and
and ![]() so that
so that ![]() and
and
![]() by simply removing the edges connecting the two parts. The cost of removing those edges is computed as the total weight of the edges that have been removed:
by simply removing the edges connecting the two parts. The cost of removing those edges is computed as the total weight of the edges that have been removed:
 |
(43) |
However, minimising the cut value encourages cutting isolated nodes in ![]() . To avoid that problem, the cost of removing edges from
. To avoid that problem, the cost of removing edges from ![]() to
to ![]() is considered as a fraction of the total weight of connections from nodes in
is considered as a fraction of the total weight of connections from nodes in ![]() to all nodes in the graph. This leads to a new cost measure called the normalised cut:
to all nodes in the graph. This leads to a new cost measure called the normalised cut:
 |
(44) |
Let ![]() be a
be a ![]() dimensional vector, that represents the partition of
dimensional vector, that represents the partition of ![]() into two sets
into two sets ![]() and
and ![]() .
. ![]() if the node
if the node ![]() is in
is in ![]() and
and ![]() if the node
if the node ![]() is in
is in ![]() . We define:
. We define:
| (45) |
Let
![]() , the total weight of edges between the node
, the total weight of edges between the node ![]() and all the other nodes in the graph. Let
and all the other nodes in the graph. Let
![]() and let
and let
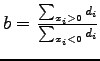 . It is proven in [87] that:
. It is proven in [87] that:
| (47) |
 is called the Rayleigh quotient [36,63]. The minimisation of equation B.4 can be approximate by relaxing
is called the Rayleigh quotient [36,63]. The minimisation of equation B.4 can be approximate by relaxing ![]() to take real values and solving the generalised eigenvalue system:
to take real values and solving the generalised eigenvalue system:
Equation B.6 can be rewritten as a standard eigensystem:
| (49) |
By observing the following:
In our case, we can conclude that ![]() minimises
minimises
 under the constraint
under the constraint
![]() . So,
. So,
![]() minimises
minimises
 under the constraint
under the constraint
![]() .
.
We need only to compute the eigenvector associated with the second smallest eigenvalue. We use the Lanczos algorithm to compute that vector. This algorithm iteratively approximates the eigenvectors until convergence [36]. In contrast to singular value decomposition, only two eigenvectors have to be computed to get the eigenvector we are looking for. This makes the Lanczos algorithm quicker, especially for large matrices.
The solution ![]() of the relaxed problem can be used as an approximate solution to the original discrete problem. We need an extra condition on the components of the solution
of the relaxed problem can be used as an approximate solution to the original discrete problem. We need an extra condition on the components of the solution ![]() :
:
![]() . In the ideal case, the components of the eigenvector takes only two discrete values, which represents the two classes. If it is not the case, we need to choose a splitting point to partition the values of the components of the eigenvector. Here we simply choose
. In the ideal case, the components of the eigenvector takes only two discrete values, which represents the two classes. If it is not the case, we need to choose a splitting point to partition the values of the components of the eigenvector. Here we simply choose ![]() as a splitting point. All the positive components represent elements from one class and all the negatives ones represent elements from the other class. Other methods exist for choosing the splitting point [89].
as a splitting point. All the positive components represent elements from one class and all the negatives ones represent elements from the other class. Other methods exist for choosing the splitting point [89].
We can then separate the set of elements into two sets, one containing the elements corresponding to positive values in the eigenvector and the other one containing elements corresponding to negative values in the eigenvector. We recursively cluster the resulting two element sets until we reach a given number of clusters.
This number of resulting clusters is usually not a power of two as one would expect given our description of the algorithm. This is due to the fact that the normalised cuts algorithm does not always separate the groups into two for each steps. It is possible that the second eigenvector given by the Lanczos algorithm has only positive or only negative values. This can be due either to rounding errors in the computation of the eigenvector or to cases where the choice of ![]() as a threshold value for selecting the two groups is a bad choice (the solution of the normalised cuts algorithm is only an approximation of the continuous case). It can also be due to the fact that the group we are trying to split only contains one element (due to previous splits). In that case, we do not split the group so the count of the number of group will not be a power of two.
as a threshold value for selecting the two groups is a bad choice (the solution of the normalised cuts algorithm is only an approximation of the continuous case). It can also be due to the fact that the group we are trying to split only contains one element (due to previous splits). In that case, we do not split the group so the count of the number of group will not be a power of two.
