This section deal with the problem of finding the right solution with an accuracy better than ![]() , if
, if ![]() is a chosen threshold.
is a chosen threshold.
In order to find the solution, we tried to predict letters given histories of letters from a learning set of letter. The learning set is text ![]() , the Matusita distance is used with the maximum likelihood estimate.
, the Matusita distance is used with the maximum likelihood estimate.
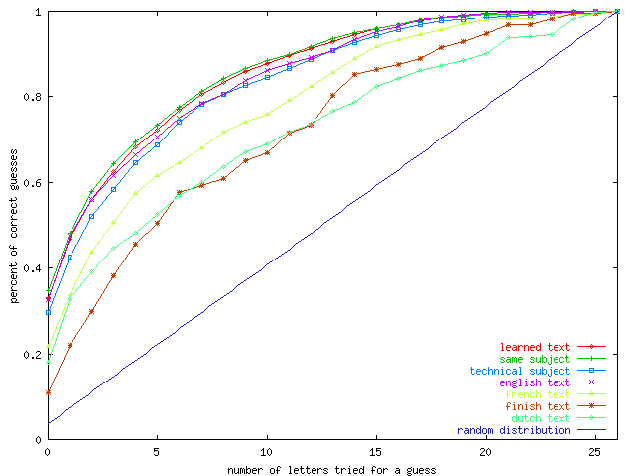
Figure 6.10 shows the cumulative percentage of correct guesses given the number of guesses tried. The different curves correspond to different test texts : the learned text (![]() ), a text on the same subject (
), a text on the same subject (![]() ), a technical text, an English text (
), a technical text, an English text (![]() ), a French text, a finish text and a Dutch text. We can see that the accuracy of the leaned VLMM tree decreases a little with the subject and decreases a lot with the language. We lose around
), a French text, a finish text and a Dutch text. We can see that the accuracy of the leaned VLMM tree decreases a little with the subject and decreases a lot with the language. We lose around ![]() of accuracy when we go from an English text to a French text, and we lose around
of accuracy when we go from an English text to a French text, and we lose around ![]() of accuracy again when we go from the French text to Nordic languages. The straight line corresponding to the case of a random prediction is drawn on the graph as a reference.
of accuracy again when we go from the French text to Nordic languages. The straight line corresponding to the case of a random prediction is drawn on the graph as a reference.
For English texts, even if the accuracy decreases a little with the subject of the text, the results seem stable. In order to achieve a accuracy of ![]() , we need to evaluate and test 15 characters to be sure at
, we need to evaluate and test 15 characters to be sure at ![]() to find the right next element. This means that half of the alphabet has to be tested to find the right element. This does not seem to be a great improvement but we hope that it is due to the large variability of the sequence of letters. If the variability of sequences of faces is smaller, the number of elements to evaluate will certainly be smaller too.
to find the right next element. This means that half of the alphabet has to be tested to find the right element. This does not seem to be a great improvement but we hope that it is due to the large variability of the sequence of letters. If the variability of sequences of faces is smaller, the number of elements to evaluate will certainly be smaller too.