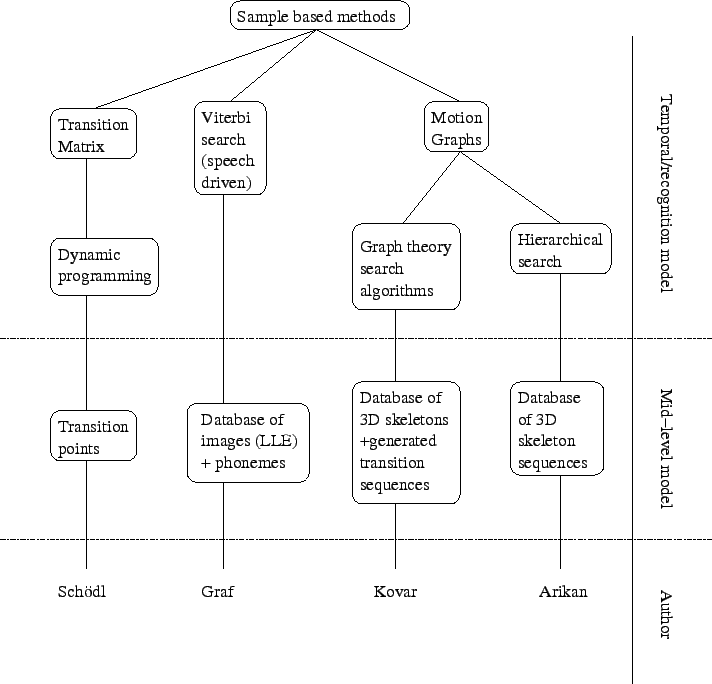
Sample based methods reuse frames from an original video sequence to generated new sequences. A tree representation of the literature on this class of generative methods can be found on figure 2.4.
Schödl et al. [86] introduce the concept of video textures. Their aim is to generate an infinitely long video sequence based on frames from an existing video sequence. Loops in the video sequence are created by jumping from one frame to another in the original video sequence. The chosen frames are selected to exhibit similar appearance and dynamics while avoiding dead ends in the generated video sequence.
Graf and Cosatto [37] use a database approach to create a talking head. Using a pre-recorded video sequence, features such as the position of the head or the size of the mouth are computed. For each frame, those features are recorded in a database along with the corresponding phoneme and the appearance of the mouth. The latter is modelled by a local linear embedding [83], which is a compression technique and provides a reconstruction of the image of the mouth close to the original image. Their aim is to create new video sequences constrained by a sequence of phonemes describing the text to be pronounced by the talking head. The new sequence takes images from an existing video sequence and overlays images of the mouth found in the database. A Viterbi search is used to find the closest appearance that satisfies the constraints and produces smooth articulation.
Kovar et al. [55] creates realistic motions of 3D skeletons from motion capture data. The original motion capture data is segmented and the segments are stored in a database. A measure of similarity is computed between each pair of frames. Local minima of this similarity measure that have a value less than a selected threshold are computed. The corresponding pairs of frames are selected to construct a motion graph that represents how we can move from one capture sequence stored in the database to another. Transition sequences between stored captured sequences are also synthesised by a linear blending technique, stored in the database and added to the motion graph. The motion graph is then pruned to avoid dead ends and to ensure that arbitrary long streams can be generated while using most of the sequences stored in the database. Sequences of 3D skeletons can then be generated by moving along the motion graph. The motion graph can also be used to find the best motion between two frames given by the user. This is done by standard graph theory algorithms that minimise a metric between two nodes on the motion graph. Metrics such as the length of the generated sequence are used. This method can be used by animators to generate realistic body motions by only specifying how the body should look for a few frames in the sequence.
Arikan et al. [2] use a hierarchical motion graph to model trajectories of 3D skeletons. As in [55], a database of capture motion data is used. The hierarchy of motion graphs is constructed so that each level represents a broader view of the motion graph of the next level. Therefore, higher levels of the hierarchy of motion graphs contain fewer nodes, each node being a representation of a group of nodes in the next level. User constraints for generating new sequences (such as contact constraints between the feet and the floor) can be applied by restricting a search to valid path examples and mutating paths in a way that preserves the constraints. The search uses high level graphs to find crude solutions while refining the solution using low level graphs.