One important point when we want to use the active appearance model to track a face is to make sure that the model is general enough. Every frame in the video sequence has to be modelled, so the appearance model used should cope with all the expression changes in the video sequence. In order to make sure the model is general enough, we construct it from frames present in the video sequence that we aim to mimic.
We mark up the first frame manually, so that the tracker knows where the face is at the beginning of the sequence, thus avoiding an initialisation procedure. Then we mark up frames that look like extreme expressions such as a large smile or a surprised expression with the mouth open. These manually marked up frames are used to construct a first appearance model of the face. This model is used to track the face through the video sequence.
For each frame tracked, we can compute the sum of squares error of the fitting using formula 3.12 . The value of this error gives a quality of fit. During the tracking, we monitor this value. If it rises above a given value, we assume that the search has failed.
The tracking typically failed on frames that contain expressions not present in the set of marked up frames used for training the appearance model. That suggested that the model was not generic enough for the video sequence. In order to make it more general, we marked up the first frame on which the tracker failed and added it to the training set of the appearance model. We can then track the sequence again with the new appearance model and repeat the procedure until the face is tracked through the whole sequence.
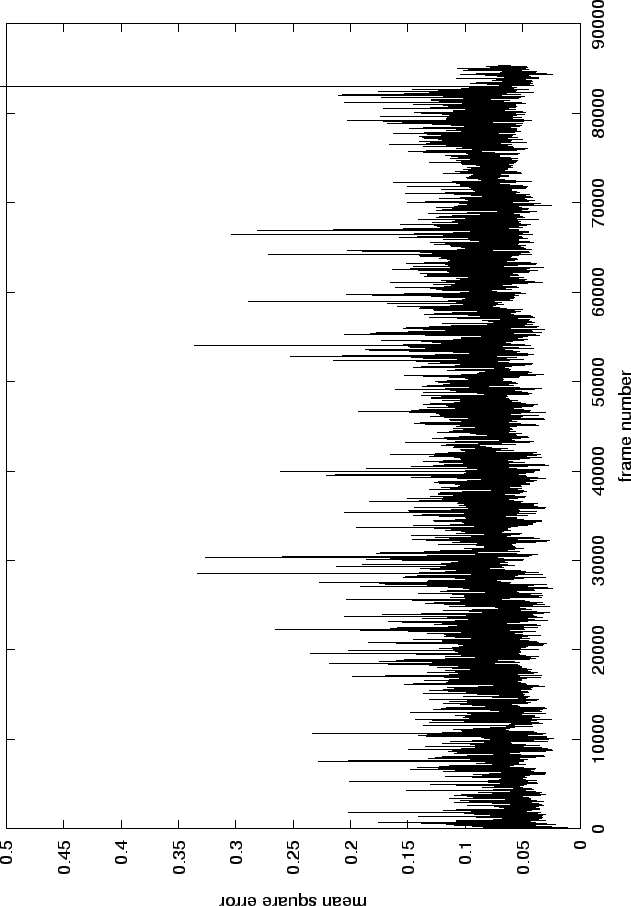
Figure 4.1 shows the final error that we obtained on a video sequence of a face talking. The large mean square errors after frame 85588 correspond to cases where a global search is needed. In practice, only 17 global searches have been applied for the face tracking on this video sequence, out of 88044 frames.
Figure 4.2 shows a visual comparison between an original frame and the reconstruction of this frame after the tracking. The reconstruction is still faithful although the error is one of the biggest error seen on figure 4.1. This shows that the sequence has been successfully tracked. The file tracked/aam_orig.m1v of the accompanying CD-ROM shows the reconstruction along with the original frames for a part of the original video sequence of figure 4.2.
 |
Although a fully automated tracking system would be desirable, in this thesis we concentrate on modelling behaviour. We are happy to accept some manual intervention in the initial tracking of the training set.