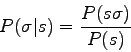One problem that arise when one deal with finite sequences is the problem of estimation of the probabilities. Indeed, the true underlying probability is not known. The probabilities must be estimated. I investigated several ways of estimating probabilities from sequences of letters (or prototypes respectively). The details of the different law of succession mentioned here can be found in [50].
In this section, we denote by ![]() the number of sequences
the number of sequences ![]() observed as being a subsequence of the training sequence. The training sequence is supposed to represent the population of sequences we will have to deal with, that is the probability distribution we want to model. We also denote by
observed as being a subsequence of the training sequence. The training sequence is supposed to represent the population of sequences we will have to deal with, that is the probability distribution we want to model. We also denote by ![]() the number of possible sequences of size
the number of possible sequences of size ![]() in the training sequence, that is :
in the training sequence, that is :
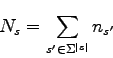
Furthermore, the conditional probability ![]() is by definition :
is by definition :