The natural law of succession presented in [51] is a more recent law of succession. It is based on the fact that simple sequences are more probable than complex sequences. The probabilities are then estimated using a more appropriate subset of the alphabet. Indeed, alphabets are large in general, and so natural sequences do not include all the element of the alphabet. That is why a new constant is introduced :
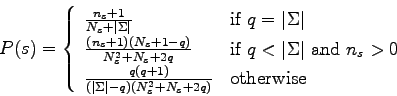
It has been proved both in theory and in practice that this law of succession outperforms the previous ones.
Unfortunately, for a practical point of view, the natural law of succession is too computationally expensive. Indeed, the computation of the formula requires to compute ![]() . The computation of
. The computation of ![]() is done by counting the size of all sets of similar subsequences of any size in the observed sequence. Furthermore, the variable length Markov model learning algorithm uses extensively the estimation of observed probabilities. So we cannot afford a lost of performance for this estimation. That is why this law of succession will not be used and assessed in the rest of this thesis.
is done by counting the size of all sets of similar subsequences of any size in the observed sequence. Furthermore, the variable length Markov model learning algorithm uses extensively the estimation of observed probabilities. So we cannot afford a lost of performance for this estimation. That is why this law of succession will not be used and assessed in the rest of this thesis.