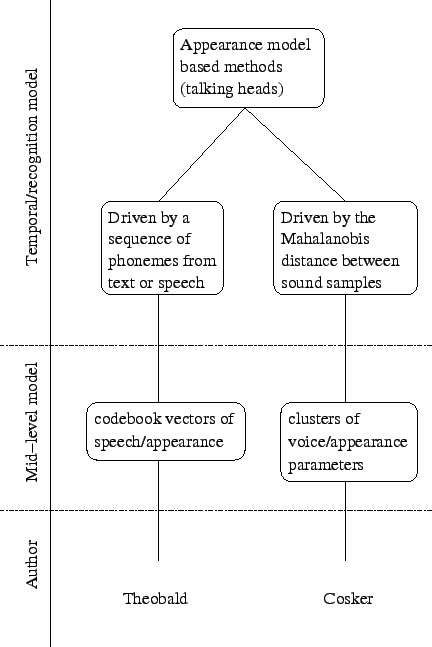
An extensive number of articles try to solve the problem of generating realistic talking heads. A talking head uses external inputs to produce the video sequence of a face. Such external inputs can be a phoneme sequence or an audio track that corresponds to the text that have to be pronounced by the head [73,67,35,44,72,31,3,43,16]. Here we concentrate only on the methods using appearance models.
Theobald et al. [93] use an appearance model to synthesise videos of a talking head based on a sequence of phonemes. The sound track is first segmented into phonemes. A set of codebook vectors is created from some training videos of someone speaking with a neutral expression. Each codebook vector encodes a phoneme and the corresponding appearance parameters. In order to create the talking head, a sequence of phonemes is given as an input to the system. This sequence can either be given manually or generated from a given audio track. A measure of similarity of phonemes and their context is used to find the closest codebook vectors to the current phoneme. The appearance parameters are then extracted from the first few codebook vectors and a weighted average used for synthesis. The resulting appearance parameters from each phoneme are concatenated together. The result is then smoothed by interpolating the sequence of appearance parameters using a smoothing spline. The parameters are synthesised back to a video sequence to produce a photorealistic head talking with a neutral expression.
Cosker et al. [25] present a talking head based on hierarchical non-linear speech-appearance models. Instead of using a standard appearance model, a hierarchical facial model is used. Several parts of the faces are modelled separately using an appearance model for each. For instance, the mouth has its own model and should capture all the possible mouth variations, even the fine details that are harder to capture with a appearance model of the whole face. This approach is similar to [94]. The appearance vectors corresponding to the parts are concatenated. The distribution of the vectors is then approximated by a mixture of Gaussians using the EM algorithm [27]. The 40ms voice data corresponding to each frame is encoded in the same way as [28] using a Mel-Cepstral analysis. It is concatenated to the appearance vector in the corresponding cluster. Each cluster is then modelled by a principle component analysis. For the synthesis, a sound sample of 40ms is presented to the system. The cluster that is closest to that sound is used for synthesis. The Mahalanobis distance is used to compute distances between the sound sample and the parameters of sound corresponding to the mean of each cluster. A linear relationship is then assumed within the cluster to map the speech parameters to the appearance parameters. After smoothing the trajectory of the appearance parameters, the face is finally synthesised by combining the reconstruction of the different appearance models used (face, mouth and eyes).
The two works can be classified as appearance model based methods in figure 2.6.